POMA AI Achieves Best-in-Class RAG Chunking and Document Ingestion With 77% Token Reduction vs. Conventional Models

Smart hierarchical chunking is the optimal data preparation for vector database embeddings
Berlin, BERLIN, March 16, 2026 (GLOBE NEWSWIRE) — POMA AI, a Berlin-based document intelligence company, today released POMA-OfficeQA, an open-source benchmark demonstrating that its structure-aware document chunking reduces RAG retrieval costs by 77% compared to both naive text splitting and Unstructured.io’s element extraction approach.
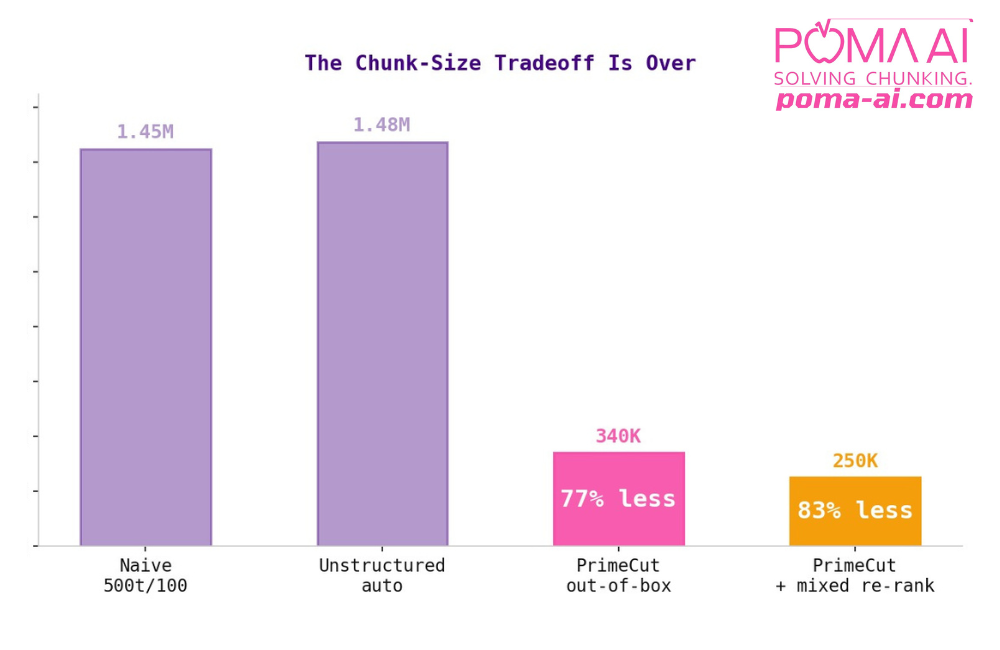
Out of the box,POMA PrimeCut uses 77% fewer tokens than conventional models. The figure rises to 83% when used in customized configurations.
“Every RAG system in production today loses information before the model even sees it,” said Dr. Alexander Kihm, founder & CEO of POMA AI. “The industry has been optimizing embeddings, rerankers, and prompt engineering, but the ingestion layer is where most retrieval failures actually originate. This benchmark quantifies what practitioners have felt intuitively: structure-aware chunking is the foundation that makes everything downstream actually work.”
The full benchmark, available on GitHub, tested three document chunking strategies for Retrieval-Augmented Generation (RAG) using identical embeddings, identical retrieval logic, and 20 table-lookup questions across 14 U.S. Treasury Bulletins (~2,150 pages). The test measured each method’s ability to retrieve all evidence required to correctly answer factual questions, with the metric (context recall) specifying the minimum token budget a retrieval system needs to guarantee all evidence is available in the retrieved context.
The results showed that POMA’s hierarchical chunking—which preserves document structure including table headers, section hierarchy, and semantic relationships between content elements—required 77% fewer tokens to achieve 100% context recall:
- Baseline (naive chunking with 500 token, 100 overlap): 1.45 million
- Unstructured.io (element extraction: 1.48 million
- POMA AI (structure-aware): 340k
All methods used OpenAI’s text-embedding-3-large model for embeddings and cosine similarity for retrieval ranking. Ground truth was established using exact chunk indices verified against source documents — eliminating false positives from coincidental numeric matches.Only questions answerable by all three methods were included, ensuring a fair comparison. Questions where any method had extraction failures (OCR errors, missing values) were excluded.
“What convinced us about POMA was the engineering rigor behind a deceptively simple insight,” said AdBlock co-founder Till Faida, an investor and advisor to POMA AI. “They went after the ingestion layer, which is the part of the pipeline that everyone assumes is a solved problem. This benchmark shows it isn’t. A 77% token reduction changes the economics of running RAG at enterprise scale. That’s the kind of structural advantage we look for.”
ABOUT POMA AI: POMA AI is a Berlin-based document intelligence company building infrastructure for enterprise RAG systems. Its core technology transforms complex documents into semantically coherent chunks ready for vector search and LLM consumption. POMA’s API processes documents in a single call and outputs both granular chunks and grouped chunksets, compatible with any embedding model and vector store. The free demo is available on POMA AI’s website. Additional information about POMA AI can be found on LinkedIn or X (Twitter).
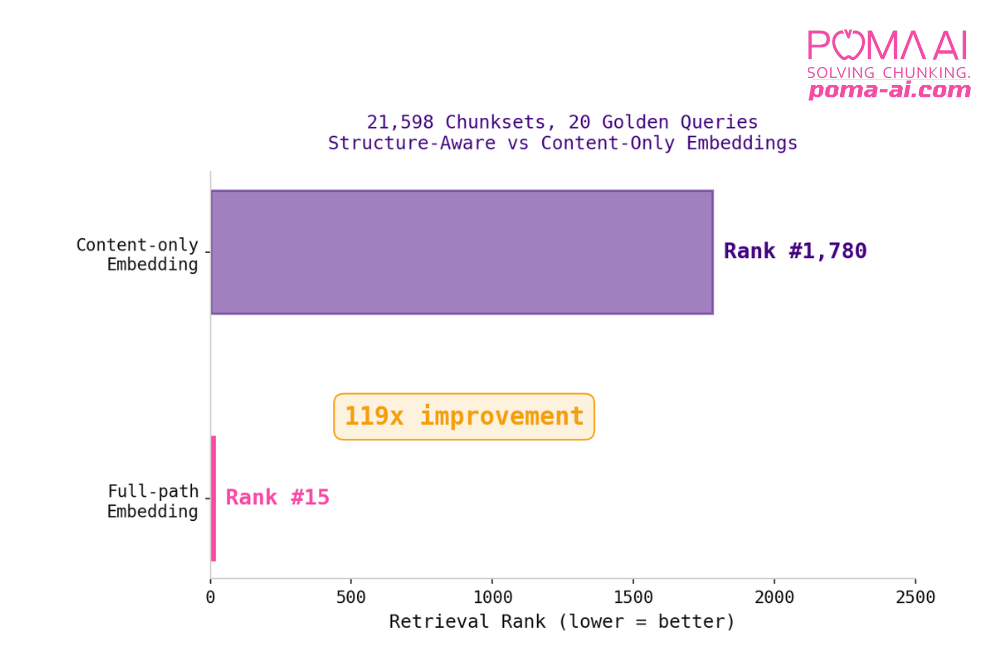
POMA PrimeCut’s structure-aware embeddings showed a 119x improvement over context-only embeddings.
Press Inquiries
Florian Athens
fa [at] poma-ai.com
https://poma-ai.com
