Numenta Achieves 123X Inference Performance Improvement for BERT Transformers on Intel Xeon Processor Family

Numenta neuroscience-based AI technology is enabling deep learning models to achieve two orders of magnitude throughput speed-up while maintaining low latencies
![]()
Transformative Possibilities for NLP and Other Real-Time Applications Through New Numenta Beta Program
REDWOOD CITY, Calif.–(BUSINESS WIRE)–#AI–Applying its decades of neuroscience research to the development of deep learning technologies, Numenta Inc. is reporting groundbreaking performance achievements in AI. In collaboration with Intel, Numenta reports it has achieved unparalleled performance gains by applying its brain-based technology to Transformer networks with Intel Xeon processors.
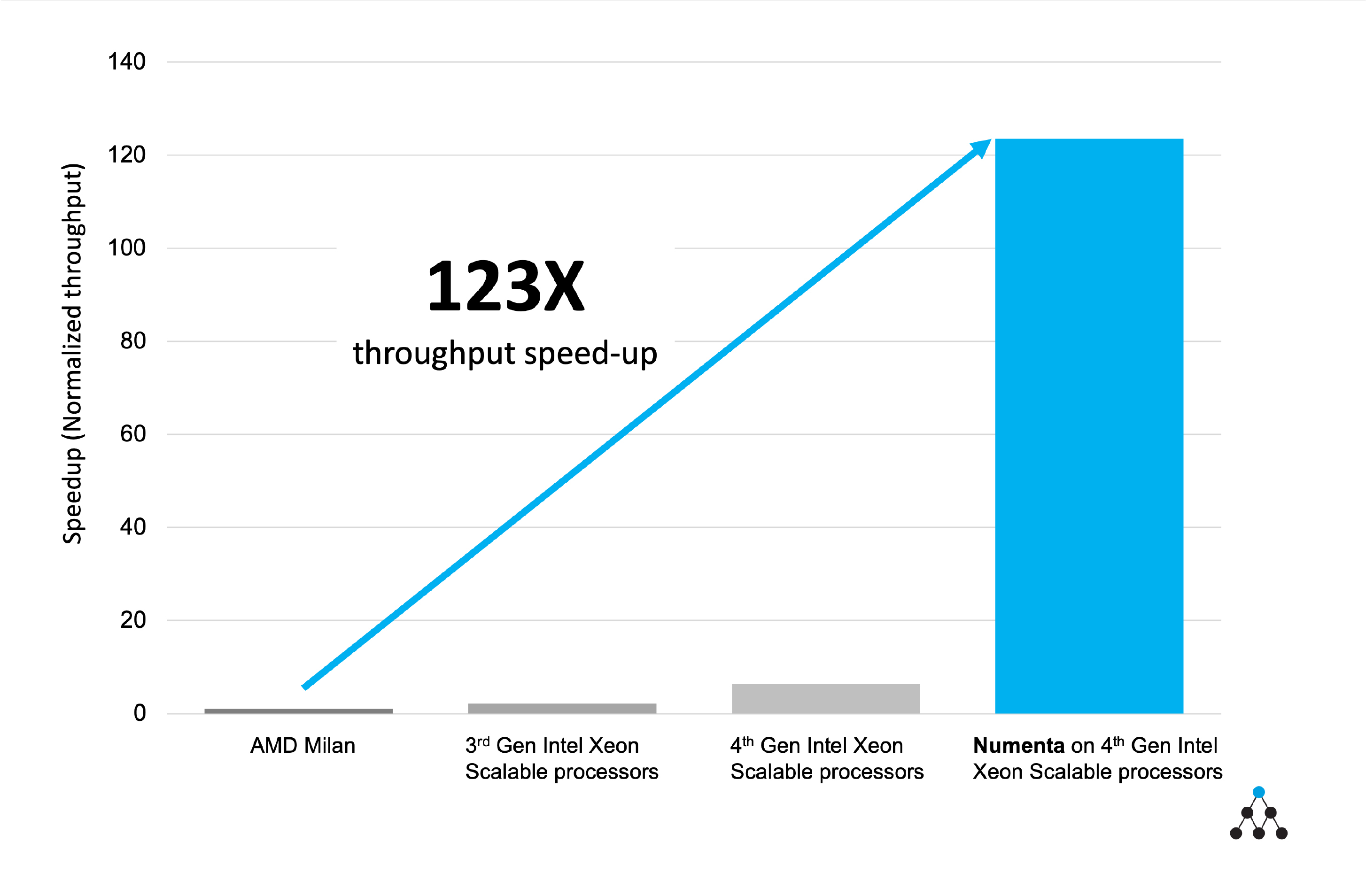
Numenta is highlighting these remarkable results on two Intel products announced today, the 4th Gen Intel Xeon Scalable processors (formerly codenamed Sapphire Rapids) and the Intel Xeon CPU Max Series (formerly codenamed Sapphire Rapids + HBM). These results demonstrate the first commercial applications of Numenta’s technology in Conversational AI solutions.
Breaking Latency Barriers in Conversational AI
To allow consumers to engage in human-like interactions with computers, high throughput, low latency technologies are a requirement for Conversational AI, a rapidly growing market projected to be a $40 billion industry by 2030. Transformer networks are the deep learning model of choice for these applications. But despite their high accuracy, the size and the complexity of Transformers have made them costly to deploy, until now.
In a remarkable example leveraging Intel’s new Intel Advanced Matrix Extensions (Intel AMX), Numenta reports a stunning 123X throughput improvement vs. current generation AMD Milan CPU implementations for BERT inference on short text sequences, while smashing the 10ms latency barrier required for many language model applications. BERT is the popular Transformer-based machine learning technology for Natural Language Processing (NLP) pre-training developed by Google.
Combining its proprietary technology with 4th Gen Intel Xeon Scalable processors, Numenta also reports a 62x throughput improvement over Intel’s previous generation of Intel Xeon Scalable processors.
Numenta’s dramatic acceleration of Transformer networks delivers high throughput at ultra-low latencies for inference with 4th Gen Intel Xeon Scalable processors. These results illustrate a cost-effective option for running the large deep learning models necessary for Conversational AI and other real-time AI applications.
“These breakthrough results turn Transformers from a cumbersome technology into a high-performance solution for real-time NLP applications and open up new possibilities for companies with performance sensitive AI applications,” commented Subutai Ahmad, CEO of Numenta. “Customers will be able to use the combination of Numenta and 4th Gen Intel Xeon Scalable processors to deploy real-time apps in a light-weight, cost-effective manner.”
“Numenta’s results on Intel’s new hardware make it possible to deploy state-of-the-art Transformers at an unparalleled price/performance point, greatly expanding the design space for conversational interaction and ultimately boosting top-line value,” said Tom Ngo, CEO of Lumin.ai, a leading Conversational AI company whose Sales Accelerator product helps high-touch sales teams in multiple industries meet with more of their prospects and shorten their sales cycles.
Unmatched Throughput for High Volume Document Processing
Numenta’s AI technology also dramatically accelerates NLP applications that rely on analyzing large collections of documents. When applying Transformers to document understanding, long sequence lengths are required to incorporate the full context of the document. These long sequences require high data transfer rates, and off-chip bandwidth thus becomes the limiting factor. Using the new Intel Xeon CPU Max Series, Numenta demonstrates it can optimize the BERT-Large model to process large text documents, enabling unparalleled 20x throughput speed-up for long sequence lengths of 512.
“Numenta and Intel are collaborating to deliver substantial performance gains to Numenta’s AI solutions through the Intel Xeon CPU Max Series and 4th Gen Intel Xeon Scalable processors. We’re excited to work together to unlock significant throughput performance accelerations for previously bandwidth-bound or latency-bound AI applications such as Conversational AI and large document processing,” said Scott Clark, vice president and general manager of AI and HPC Application Level Engineering, Intel.
“This type of innovation is absolutely transformative for our customers, enabling cost-efficient scaling for the first time,” added Ahmad.
NUMENTA LAUNCHES BETA PROGRAM
To provide the benefit of its AI products and solutions to customers as quickly as possible, Numenta recently announced a Private Beta program. Numenta is actively engaging with startups and Global 100 companies to apply its platform technology to a broad spectrum of NLP and Computer Vision applications.
Customers can apply for the Beta Program at https://www.numenta.com/beta/.
About Numenta
Numenta has developed breakthrough advances in AI technology that enable customers to achieve from 10 to over 100X improvement in performance across broad use cases, such as natural language processing and computer vision. Founded in 2005 by computer industry pioneers Jeff Hawkins and Donna Dubinsky, Numenta has two decades of research deriving proprietary technology from neuroscience. Leveraging the fundamental insights from its neuroscience research, Numenta has defined new architectures, data structures and algorithms that deliver disruptive performance improvements. Numenta is engaged with several Global 100 companies to apply its platform technology across the full spectrum of AI, from model development to deployment – and ultimately enable whole new categories of applications.
Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries.
Contacts
Betty Taylor for Numenta
Betty.tlr@gmail.com