The Full Guide to AWS Lambda Cold Starts

Introduction
The modern-day serverless function came into formal existence when Dr. Werner Vogels unveiled AWS Lambda to an ecstatic crowd at AWS’ esteemed re:Invent in the cold month of November 2014. Ever since, then serverless has boomed in popularity and adoption. The cloud concept has witnessed tremendous growth rates as mentioned in the ResearchAndMarkets.com’s report titled “Serverless Architecture Market by Deployment Model, Application, Organization Size, and Industry Vertical: Global Opportunity Analysis and Industry Forecast, 2018-2025”. As per the findings of the report, the global serverless market size was valued at $3,105.64 million in 2017 and is projected to reach $21,988.07 million by 2025, registering a CAGR of 27.9% from 2018 to 2025.
These numbers recorded and interpolated echo in various other reports and market research findings conducted by companies and organizations across the tech community. These trends manifesting the popularity of serverless arise from the benefits of the technology. With the advancement in software development, the question no longer is centered around whether or not to move to the cloud, but how to do so, and it seems serverless is the answer.
Serverless no doubt has been gaining popularity. This is because serverless provides solutions to the woes of developing in the cloud seamlessly, requiring little or no effort. These solutions come in the form of the three characteristics listed below.
- Fully managed: You now no longer have to worry about building and maintaining any underlying architecture, delegating all responsibilities to the cloud vendor.
- Scalable: Gone are the days when we had to forecast resource usage to ensure we always have the right amount of resources to host our applications in an everchanging environment of customer demands.
- Pay-as-you-go: Only pay for those resources you’re using. As compared to other cloud resources such as the IaaS compute service AWS EC2 where you would be paying for the instance even when there is no traffic.
Nevertheless, there are of course, as with other cloud solutions, disadvantages that juxtapose these major advantages. One drawback, however, is primarily the cause of performance problems resulting in an overbearing barrier to adoption. Cold starts.
The serverless cold start problem is the latency that is incurred when running the serverless function after a certain period of idleness. This latency for the customer means a delay in the request processing, long loading periods, and in general a failure to serve time-sensitive applications. In fact, the issue was voted the third most concerning issue by the serverless community in the 2018 Serverless Community surve, in terms of performance roadblocks
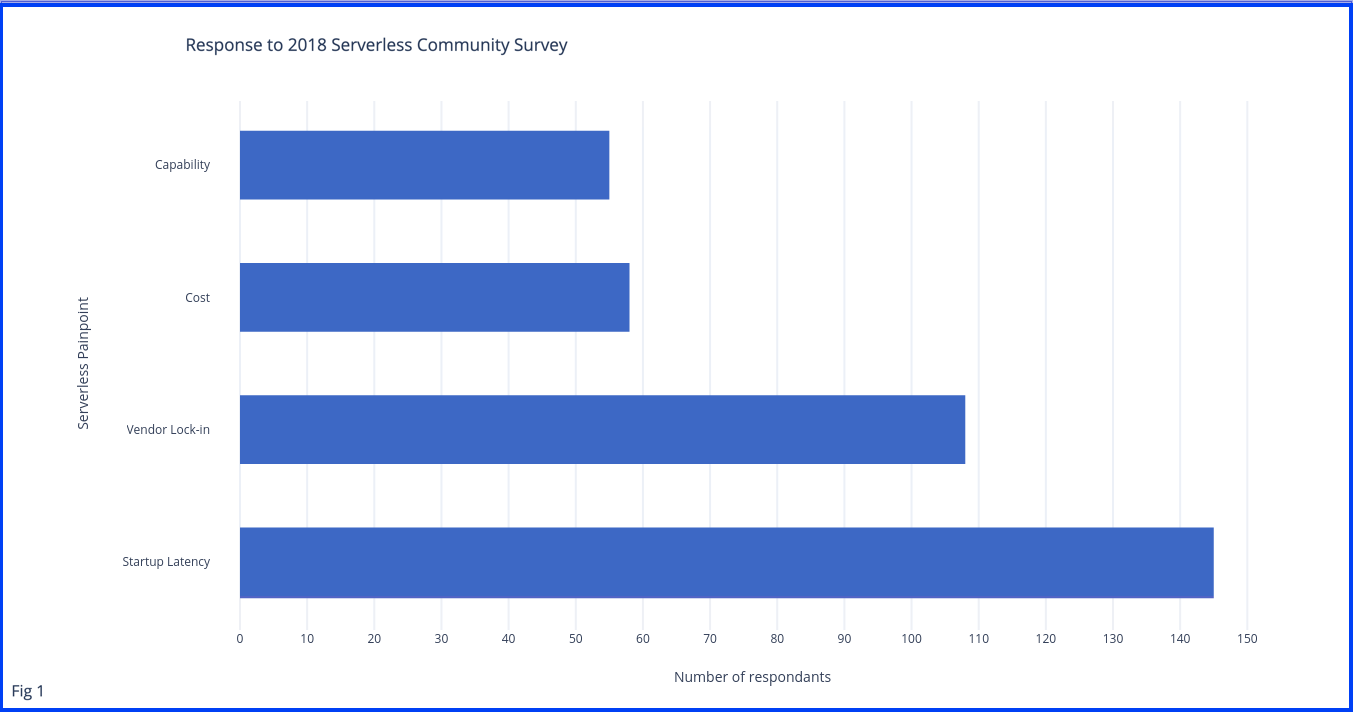
The issue may seem like a deal-breaker for a lot of potential adopters, however, there are solutions to overcome the cold start barrier. Therefore, this whitepaper, aims to understand the core root of the cold start problem in AWS Lambda functions, its effect across serverless applications and how can these effects be mitigated by a plethora of best practices and engineering solutions.
Cold Starts as an Inherent Problem
To understand the solution to cold starts we need to understand why cold starts occur in the first place. They could generally be defined as the set-up time required to get a serverless application’s environment up and running when it is invoked for the first time within a defined period. With this understanding, we also accept that cold starts are somewhat of an inherent problem with the serverless model.
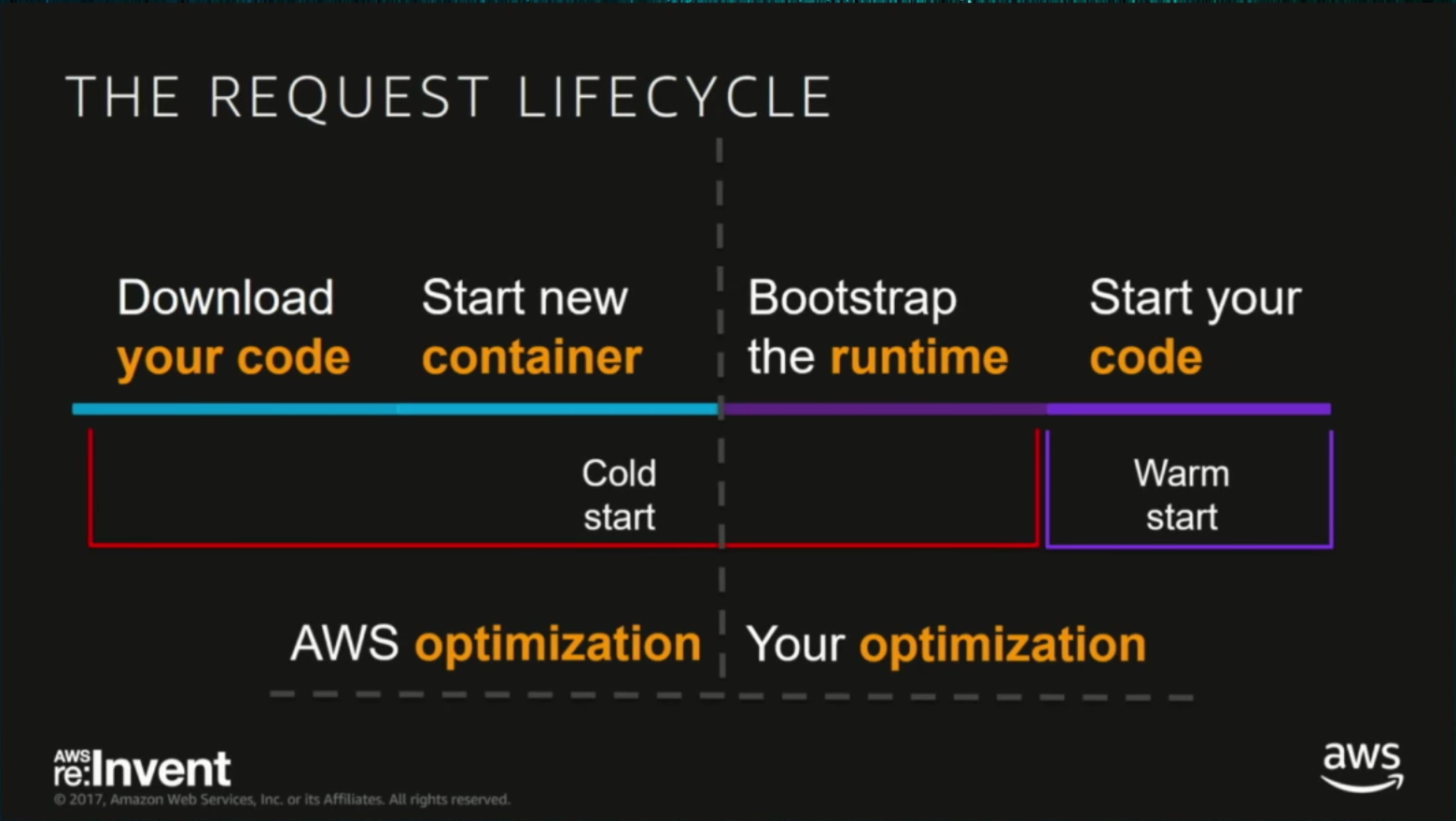
Serverless applications run on ephemeral containers, the worker nodes, where the management of these nodes becomes the responsibility of platform providers. That is where the wonderful features of auto-scalability and pay-as-you-go arise since vendors such as AWS can manage the resources to match exactly the requirements of your application running.
The problem here though is that there is latency in getting these worker nodes in the form of ephemeral containers up for your first invocation. After all, the serverless principle is that you utilize resources when required. When not required, those resources theoretically do not exist, or at least you don’t have to worry about them.
The issue is further exasperated by the fact that it is not completely possible to know when these worker nodes would be torn down after a period of idleness. If the serverless function is continuously being invoked within short periods of time, the possibility of the worker node being torn down is low. However, as the periods of idleness increases, the possibility of the worker node being no longer available for the next inevitable invocation is greater. Additionally, the possibility of worker nodes being torn down also depends on the amount of compute resources reserved by the ephemeral container.
For example, AWS Lambda functions with greater memory allocated can not sustain relatively long periods of idleness. The vendor solution would rather have a considerably larger amount of compute resources allocated to other more active functions than being reserved for idle functions. This was explored extensively by Kevin S. Lin and AWS hero Yan Cui.
The reason for handling the ephemeral containers, servicing worker nodes, in this manner is to enable the benefits that serverless promises. Servicing serverless functions is costly as more of the responsibility falls on the vendor. The reality is that there is no infinite number of resources to keep allocated to each function, hence the pay-as-you-go model and auto scalability.
It is thus this unavoidable latency that actually degrades the performance of your applications. This is especially true when you are building serverless applications that are meant to be time-sensitive, almost all customer-facing applications.
Cold Start Latency in Numbers
Cold starts as described are an inevitable problem of serverless functions, originating from the same characteristics of serverless that makes it a desirable solution. In essence, it is unavoidable and so the question is what are the effects of cold starts on serverless applications and how cold starts vary across the types of serverless functions built.
The effect of cold starts was measured on varying AWS Lambda function types. The parameters that were varied were the language type and the memory allocated to the Lambda function. All the Lambda functions were kept constant in terms of their functionality. They were all meant to simply print out the famous ‘Hello World’ message on the console.
Each Lambda function was invoked a total of three times, with substantially long waiting periods between them to ensure that the invocation is a cold start. Thundra was used to verify that the test invocation was indeed a cold start using as the tool helps differentiate different types of invitations. The cold start durations were then measured using the insights received from the Thundra console and were recorded and visualized in Fig 2.1.
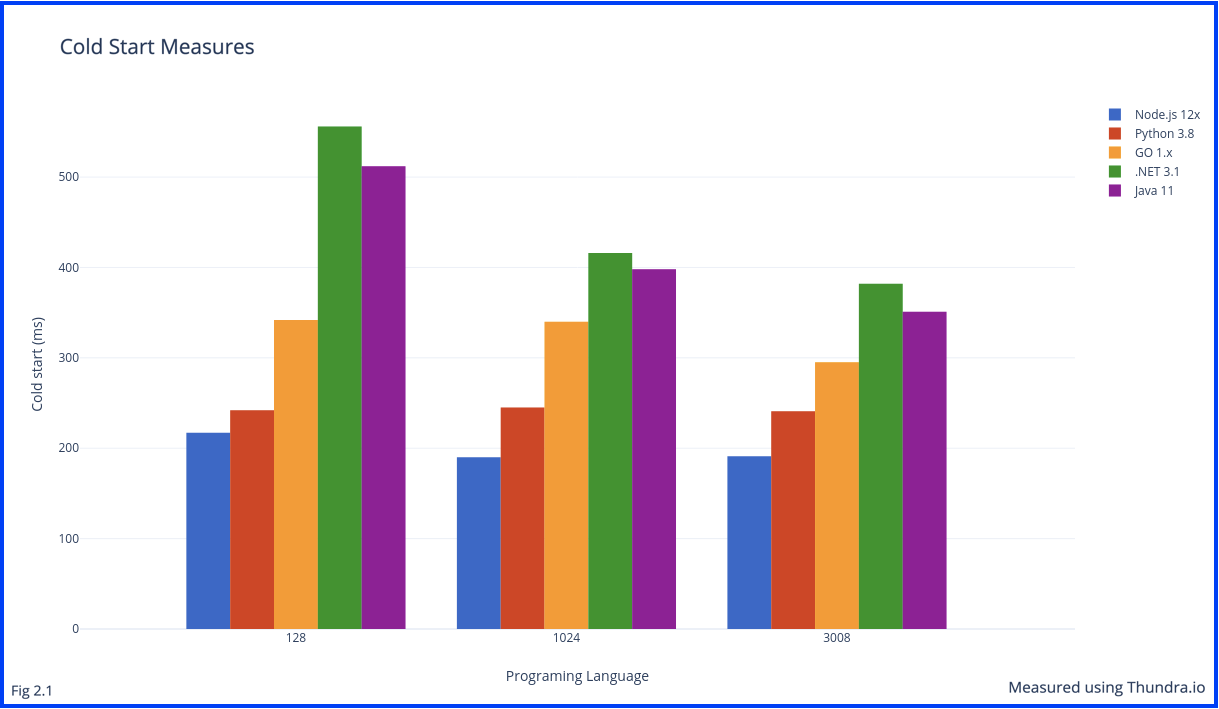
From the graph in Fig 2.1, it can immediately be noticed that statically typed languages fare much worse as compared to their counterparts. Thundra was used to measure five language types which include Node.js 12.x, Python 3.8, GO 1.x, .NET 3.1, and Java.
.NET 3.1 and Java had significantly higher cold start duration as compared to Node.js and Python with Node.js being the evident winner. .NET cold start durations were the worst in all tests.
This is expected considering the initialization of worker nodes during the cold start of serverless functions. Using statically typed languages means that the container environment that is set up needs to initially be aware of the variable types. However, Java is also a statically typed language but we do not see the same horrific cold start durations as we do in .NET.
Another observation made was the effect of function memory allocated. The higher the memory the lower the cold start duration in general. The effect of this was more visible on statically typed languages as compared to Python and Node.js. Increasing memory may not always be a viable option, however, as it also could result in more frequent cold starts considering that there is a higher probability of worker nodes being torn down when allocated more compute resources.
The effect of cold starts is put into perspective when comparing the results to the durations recorded of warm invocations. The same functions were also invoked when warm, and recorded by Thundra which also validated that the invocation did not lead to a cold start. The results of invoking a function when warm was collected by sending a second invocation immediately after the initial invocation of the test function resulting in a cold start. The results can be seen in Fig 2.2.
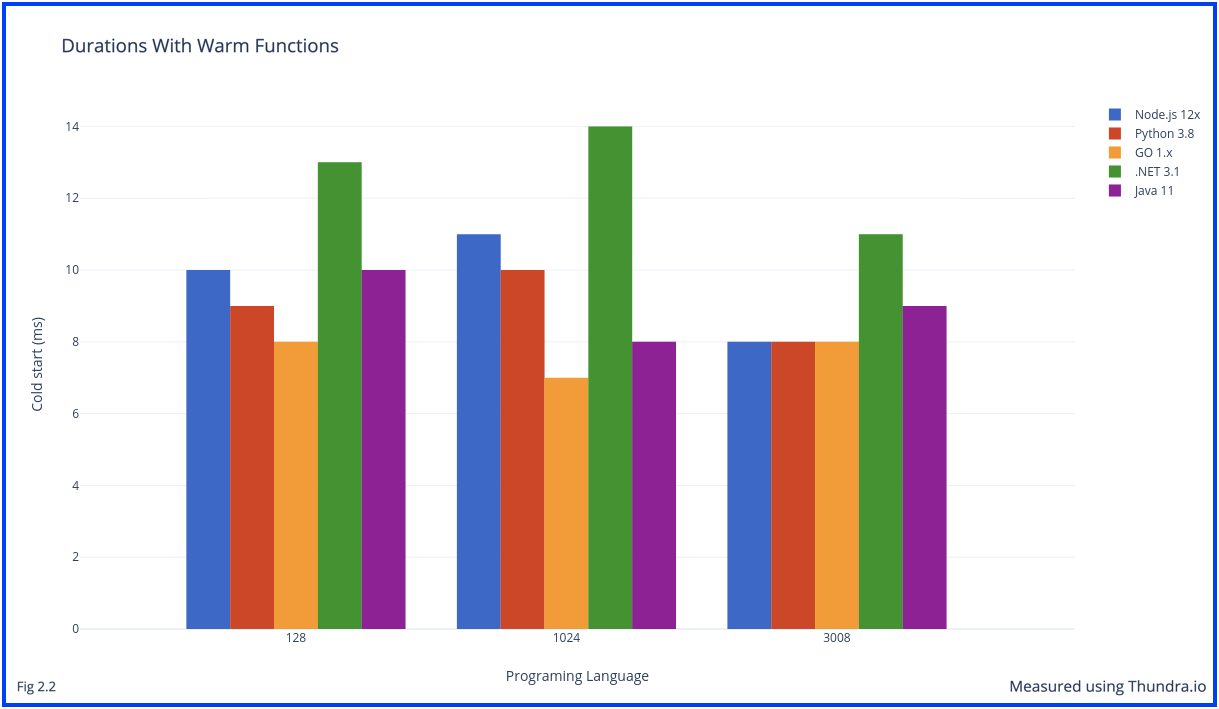
Comparing Fig 2.1 and Fig 2.2, it is evident that cold starts have a major impact on the performance of the function. However, apart from the properties of the Lambda function itself, external factors and other architectural components can also have an effect on the experienced cold start durations.
Nevertheless, it is understood that cold starts are, unfortunately, an intrinsic part of serverless. The exact impact on invocation duration depends on various factors such as the programming languages and frameworks being used, the configurations of your Lambda functions, and the associated resources.
Remedies for the Cold Start Flu
Cold starts are undoubtedly problematic to users of serverless functions. Nevertheless, there are several solutions and best practices that you can employ to mitigate these pains and overcome the hurdles created by cold starts. Here are some of the major solutions and best practices that you can apply.
Avoid Enormous Functions
Larger serverless functions mean more set-up required for the vendor and therefore, greater clod start durations. Deciding how large your Lambda function should be is a skill that should be mastered, especially with the advent of microservices in the cloud. Serverless gives a great motive to us in breaking down large monolithic beasts into separate serverless functions. The question is how granular should you go?
Having too many Lambda functions means having to maintain a more complex architecture and potentially endure higher costs of operation. On the other hand, putting all your business logic and code into a single Lambda function could lead to higher cold starts. Other issues also include greater potential for timeouts as AWS Lambda has a 15-minute runtime limit.
Image of how cloud architecture can change from simple to complex procured from Emrah abi’s Pokemon analogy.
It thus seems like a delicate balancing act. The solution is employing the best practices according to how you structure your architecture and enhance your decisions by continuously monitoring the performance of your serverless applications. Take advantage of serverless monitoring tools to enable you to get the relevant insights. For example, you can use Thundra to monitor invocation durations of your Lambda functions along with function costs. Use this information to decide whether or not to further split Lambda functions or consolidate them to save invocation costs.
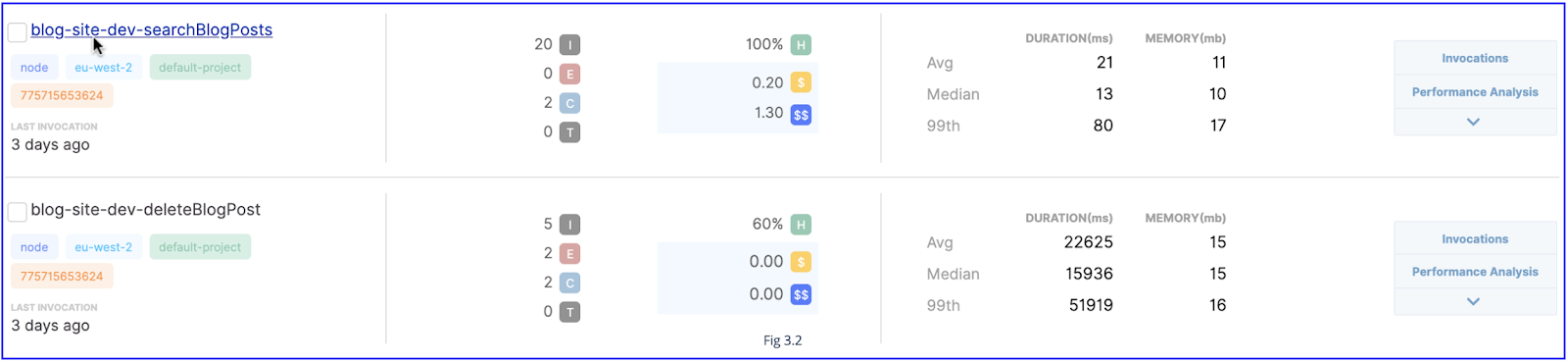
Reduce Set-Up Variables
When the serverless container is being prepared, it involves setting up static variables and associated components of a static language such as C# and Java. Hence one of the easiest and quickest practices that can be implemented is to ensure no unnecessary static variables and classes.
The impact this solution has on the cold start duration is dependent on the initial function size and complexity of your serverless. Do not expect to see any significant gains in performance simply by removing a handful of static variables. Unfortunately, the impact of avoiding a single static variable is greatly insignificant, and the scale at which the solution must be practiced for notable reductions in durations definitely transcends the scope of the average Lambda. Nevertheless, this is the simplest solution and must unequivocally be realized.
Adjust Allocated Memory
When uploading your code to the AWS Lambda you can also adjust compute metrics such as how much memory to dedicate to a Lambda. The amount of memory dedicated to a Lambda also results in proportional CPU cycles being dedicated to the Lambda.
This solution seems to have more effect on static languages as compared to dynamically typed languages. This is validated by the results, in Fig 3.3 when comparing the effects of memory allocation on Node.js and .NET.
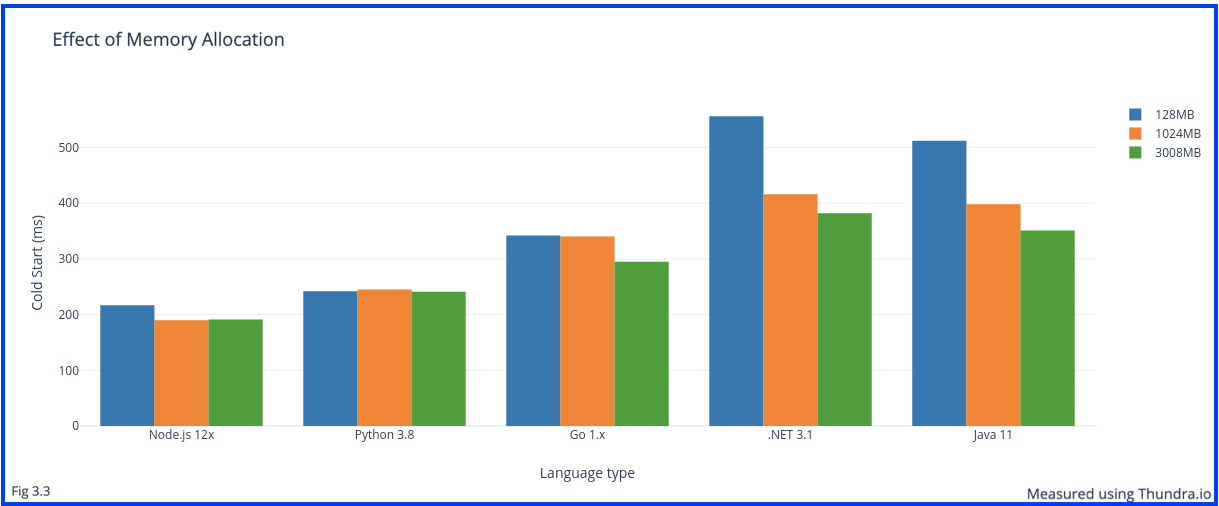
The differing effects can be attributed to the fact that setting up the static environment requires CPU work to deal with static properties and weight of memories. Ensuring that the .NET function gets adequate CPU power directly relates to lower cold start durations. This is exactly what is observed in Fig 3.3.
Keeping Functions Warm
This method aims at reducing the cold start frequency, and in an ideal world, eliminate cold starts completely. It involves periodically sending invocations to the serverless function to simulate perpetual activity.
Deciding the frequency at which to send these warming invocations requires monitoring and fine-tuning. You do not want to bombard your serverless function with too many empty invocations as it can lead to unnecessary costs due to the pay-as-you-go model of AWS Lambda. On the contrary, you also do not want to have a frequency that fails to reduce the recurrence of cold starts. It is difficult to know what time of idleness is allowed to a container before it is closed. Hence implementing the solution means monitoring the regularity of cold starts and increasing the frequency of warming invocations if the rate of cold starts increases, and vice-versa.
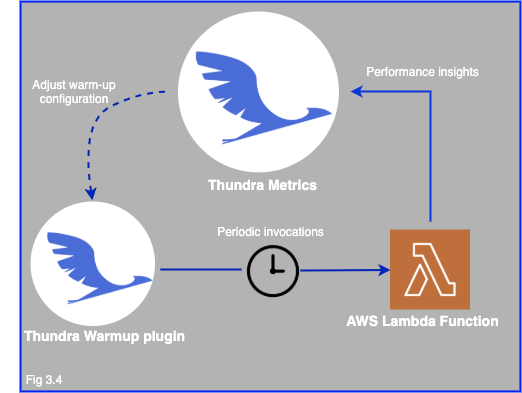
Apart from manually setting up triggers and monitoring your Lambda function to conduct the necessary fine-tuning, you could leverage Thunsra.io’s warm-up functionality. Thundra will help you manage your warm-up invocations, helping you achieve the optimum frequency to maintain.
Provisioned Concurrency
Knowing that the major reason behind cold starts is the time taken to initialize the computing worker nodes, AWS’ Provisioned Concurrency solution is quite simple. Already have those worker nodes initialized!
The concept here is that you can now decide how many of these worker nodes you would like to keep initialized for your time-sensitive serverless applications. These worker nodes will reside in a frozen state with your code downloaded and underlying container infrastructure all set. Hence technically still not using up any resources, the benefit here is a guaranteed response time of almost double-digit milliseconds.
That means, depending on the number of concurrent worker nodes you have, invocations shall be routed to provisioned worker nodes before on-demand worker nodes, thus avoiding cold starts due to the need for initialization. It would thus be wise to provision a higher number of worker nodes for expected spikes in traffic. For example, a movie ticketing system could expect a higher rate of traffic on their site at the time ticket sales of a popular show go on sale as shown below.
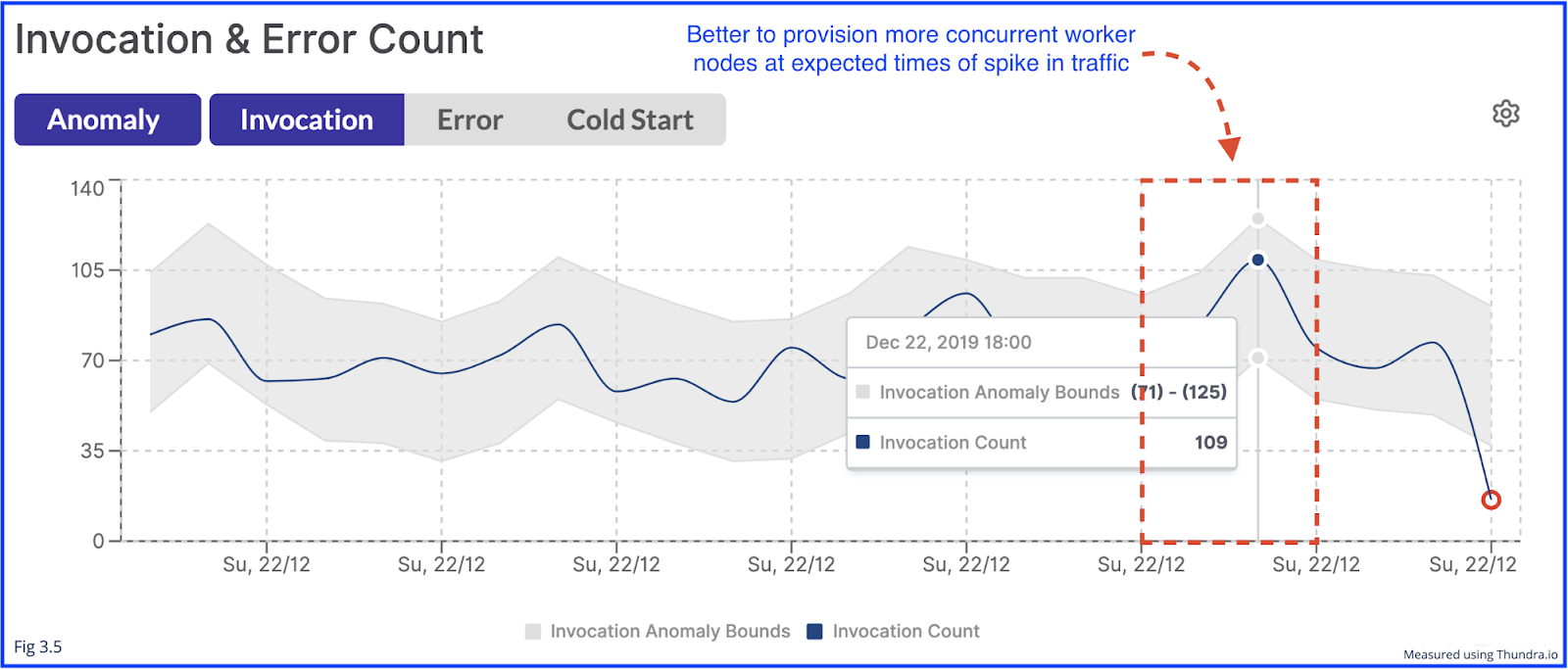
If the tickets go on sale at 6 pm, then you would expect a higher number of requests, meaning a higher number of invocations of the function. As ticket sales continue and all the show’s tickets get sold out, you can then expect traffic to drop. Therefore, you would no longer need as many provisioned concurrent worker nodes.
If the provisioned concurrent worker nodes fail to accommodate all incoming invocations, then the overflow invocations are handled conventionally with on-demand worker nodes being initialized per the request. However, overall it is definite that there is an improvement in the latency displayed by your serverless application.
Moreover, with the launch of provisioned concurrency, AWS has partnered with third-party partner tools to facilitate the provisioning of these concurrent worker nodes. For example, Thundra is one such partner and allows you to monitor these provisioned worker nodes, including the number of provisioned concurrent nodes compared to invocation spill over invocations that get routed to on-demand worker nodes. This can be seen in Fig 3.6.
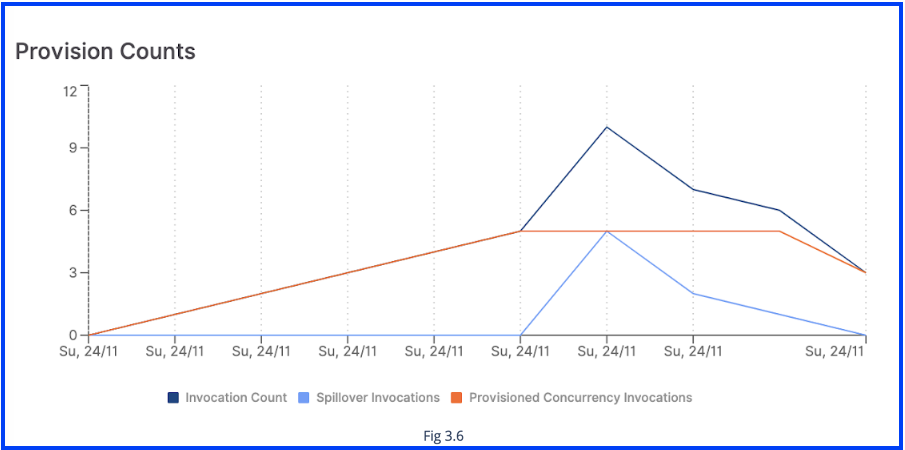
As a result, we see that vendors are proactively trying to reduce the experienced latency of using their serverless solutions by providing the capability of “reserving” ephemeral containers. This allows users to overcome the core inherent problem of cold starts as discussed above. However, this solution is susceptible to a more philosophical argument of what serverless actually means, and if the solution itself preserves the values of serverless.
In terms of AWS’ provisioned concurrency, we see a divergence from these values of serverless. Firstly, you have to manage the number of reserved worker nodes, and secondly, you have to pay for these worker nodes by the hour according to AWS’s pricing plans for the feature.
Thus it must be acknowledged that to achieve full ideal independence from the cold start problem in terms of AWS, Lambda functions may no longer be fully managed as per the ideological definition of a serverless service. Additionally the value of the pay-as-you go model also diminishes in its shine. Nevertheless, this may simply be regarded as the small price to pay to tackle the cold start problem at its core.
Conclusion
Cold starts exist in the serverless domain just like road accidents exist in the automobile industry. And just like the automobile industry’s innovative solutions, there too exists a treasure chest of solutions and best practices to the cold start problem. Afterall the exhilarating speed of man’s progress is not easily stifled by frigid walls, all barriers can be overcome. So keeping that in mind, we at Thundra wish you godspeed on your journey in the cloud with Thundra.
Whitepaper courtesy of https://www.thundra.io/