The Hidden Risk in Your AI Stack (and the Tool You Already Have to Fix It)
Screenshot
Why OCI Artifacts are the standard for production-grade model delivery
By Brad Micklea
In 2024, a large e-commerce platform rolled back their AI recommendation agent two weeks after it was initially deployed. This should have been a non-issue, but due to avoidable issues, the whole e-commerce platform crashed – resulting in $3.2 million in lost revenue over the 8 hours it took to address the problem.
The cause wasn’t the AI model – it was the rollback process which was incomplete and missed critical dependencies.
This is only the most striking example of a disturbing (and avoidable) trend. Surveys have found that >60% of organizations experience a significant production issue after rolling back AI models or agents. The average cost of those incidents is >$400K.
This Is A Business Risk Issue
| “But it worked on my machine!” |
Before containers, software teams used to hear this constantly. Code would run fine on one laptop but crash in staging. Dependencies, system packages, file paths — everything was brittle and hard to standardize. It slowed down shipping and made rollbacks risky and damaging.
Now, AI/ML teams are having the same experience, but with bigger models and messier environments.
If you’re a DevOps lead, ML engineer, or security architect trying to bring AI to production safely you’ve probably seen it: a model that runs perfectly in a Jupyter Notebook or an experiment tracker like MLflow or Weights & Biases takes weeks to reproduce in staging or on another developer’s machine.
Or maybe you’re an engineer trying to re-run an old experiment and getting different results because the model weights or dataset were changed in place.
One consulting company lost weeks of revenue when a customer pulled the wrong version of the validation dataset as part of their user acceptance testing.
And the pressure is growing. The EU AI Act, NIST AI RMF, and ISO 42001 are demanding traceable, governed, auditable AI systems in the private- and public-sector.
The shift from experimentation to production — and from sandbox to regulation — means this problem is no longer academic. It’s operational, financial, and legal.
We solved this for software with containers, and we can solve it for AI models and agents.
Containers Fixed DevOps. Models Need the Same.
Containers didn’t just make apps portable — they made them repeatable, secure, and trackable. Once code is wrapped in a container, it behaves the same on a laptop, in CI, or on Kubernetes. You can version it. Sign it. Audit it. Promote it from dev to prod without surprises.
So… what’s the equivalent for machine learning?
Today, teams ship models as loose files: a .pkl here, a config.yaml there, or a weights blob in an S3 bucket. It works for development, but it’s not enough for production, and certainly not for auditors.
What we need is a way to package entire AI/ML projects so they can be reproduced anywhere by anyone for any reason. That means models, datasets, metadata, validation scripts, dependency manifests — everything in a versioned, signed, portable unit.
That’s what OCI Artifacts provide.

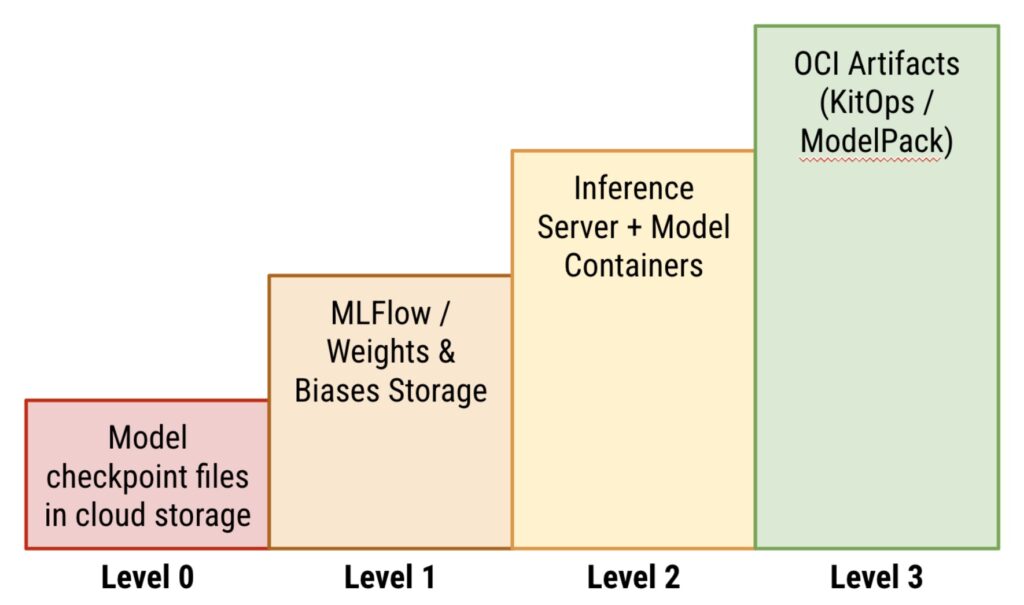
Maturity levels for packaging, versioning, and deploying AI/ML projects
What Are OCI Artifacts?
OCI (Open Container Initiative) Artifacts are a generalization of what most know as docker images. They’re built on the same foundation — layers, manifests, digests — but they aren’t limited to app containers. You can use them to package anything, including machine learning models.
OCI Artifacts allow you to package each part of your AI/ML project as its own layer – imagine it as a chest of drawers where one drawer holds the model, another the dataset, a third the code, and so on.
An OCI Artifact for a support AI project would look like this:

A recipe for an OCI Artifact containing an AI model, its training dataset, and code
Using OCI Artifacts for AI/ML projects gets you:
- Immutability — every artifact has a unique digest (no “silent updates”)
- Versioning — clear history and rollback paths
- Portability — push/pull from any OCI-compliant registry
- Security — sign artifacts, attach attestations, or build SBOMs
- Compatibility — integrates with Kubernetes, CI/CD, GitOps
You don’t need to buy a new registry. You use the one you already have — but now, for models.
Why Not Just Use a Container?
Some teams try to achieve the same goals by baking their model into a docker container. It’s tempting — you get a runtime and a deployment target in one. But that approach has drawbacks:
- You lose separation of control: the model can’t be promoted or signed independently of the container runtime.
- You lose critical context: datasets, metrics, documentation, and licenses aren’t part of the image and may get lost entirely.
- You lose auditability: when artifact and execution are merged, proving provenance and compliance becomes a nightmare.
OCI Artifacts solve this cleanly: package the model as an artifact, deploy it as a container (or however you like).
| Traditional Packaging | OCI Artifacts |
| Models versioned by filename in S3 | Model packages versioned & signed in registry |
| Datasets in CSVs, databases, etc… | Datasets stored with related models |
| No provenance | Traceable digests + SBOMs |
| Untracked changes | Immutable & attestable |
Table comparing traditional packaging approaches and an OCI Artifact based approach
How Do You Get Started?
The best part is that you can reuse much of your current tooling. If you’re using:
- Container registries → you’re ready to store OCI Artifacts
- Kubernetes or any serving platform supporting containers → you’re ready to deploy them
- CI/CD pipelines → you’re ready to automate packaging and promotion
Anything that works with containers, works with OCI Artifacts.
Tools like CNCF’s KitOps (with its CLI and Python Library), OMLMD, and others make it easy to wrap your models in a proper OCI Artifact. And with the emergence of the Cloud Native Computing Foundation’s ModelPack specification, there’s a shared schema that vendors or individuals can use to build their own implementations.
The Ecosystem Is Catching On
Over the past year, multiple open source and commercial projects have started packaging models as OCI Artifacts – proving their value:

The evolution of AI/ML packaging using OCI Artifacts
- KitOps (March 2024) — open source CLI and Python SDK for model, dataset, code, docs, and metadata packaging and versioning for local or at-scale deployments, authored by Jozu
- OMLMD (July 2024) — Python SDK from Red Hat for model + metadata packaging
- ModelPack (Feb 2025) — vendor-neutral spec from CNCF for a universal model artifact structure, authored by Jozu, Paypal, Red Hat, and ANTGroup
- Docker Model Runner (June 2025) — Docker’s new initiative for distributing LLMs as OCI Artifacts for local execution
This isn’t a trend — it’s a tidal shift. From infrastructure teams to platform vendors, everyone is aligning around OCI.
Models Deserve What Applications Have
Even enterprise ML teams are living in their “before containers” era — scripts that work in one place, models that mutate silently, and deployments that feel more like art than engineering.
We’ve been here before with software – let’s learn from those mistakes.
AI models and agents deserve the same maturity, security, and trust as the applications they work with.
OCI Artifacts deliver that. And the ecosystem is accelerating: Standards are forming, vendors are aligning, and AI models and agents are running in production this way.
The fix is here. The momentum is real. Don’t be the one catching up later.
Author Biography

Brad Micklea is Founder & CEO of Jozu and Project Lead for KitOps.org, an open source MLOps project focused on packaging AI/ML models for enterprise deployment. With over 20 years leading growth businesses and open source initiatives, Brad specializes in DevOps, developer tools, and MLOps.
Previously, Brad served as GM of Amazon API Gateway and VP of Developer Tools at Red Hat. He co-ran Codenvy through its acquisition by Red Hat and led the open source Eclipse Che project. His experience spans leadership roles at Quest Software, BlueCat Networks, and Sitraka Software, with a track record of successful exits and revenue growth.
A former JavaOne Rock Star, Brad holds a BA in Literature from McGill University and is based in Toronto, Canada.